publications
2025
-
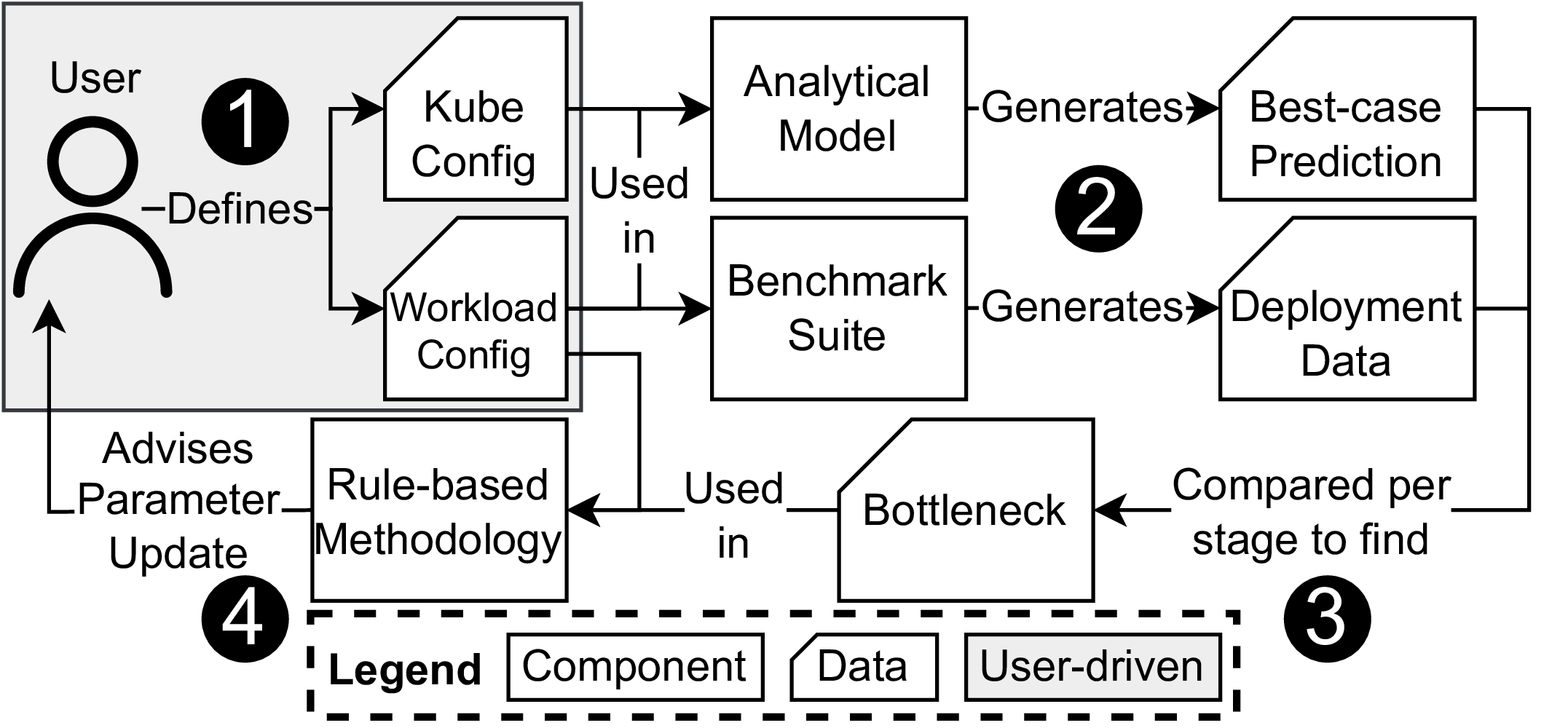 Columbo: A Reasoning Framework for Kubernetes’ Configuration SpaceMatthijs Jansen, Sacheendra Talluri, Krijn Doekemeijer, Nick Tehrany, Alexandru Iosup, and Animesh TrivediIn Proceedings of the 16th ACM/SPEC International Conference on Performance Engineering, ICPE 2025, Toronto, Canada, May 5-9, 2025, 2025
Columbo: A Reasoning Framework for Kubernetes’ Configuration SpaceMatthijs Jansen, Sacheendra Talluri, Krijn Doekemeijer, Nick Tehrany, Alexandru Iosup, and Animesh TrivediIn Proceedings of the 16th ACM/SPEC International Conference on Performance Engineering, ICPE 2025, Toronto, Canada, May 5-9, 2025, 2025Resource managers such as Kubernetes are rapidly evolving to support low-latency and scalable computing paradigms such as serverless and granular computing. As a result, Kubernetes supports dozens of workload deployment models and exposes roughly 1,600 configuration parameters. Previous work has shown that parameter tuning can significantly improve Kubernetes’ performance, but identifying which parameters impact performance and should be tuned remains challenging. To help users optimize their Kubernetes deployments, we present Columbo, an offline reasoning framework to detect and resolve performance bottlenecks using configuration parameters. We study Kubernetes and define its workload deployment pipeline of 6 stages and 26 steps. To detect bottlenecks, Columbo uses an analytical model to predict the best-case deployment time of a workload per pipeline stage and compares it to empirical data from a novel benchmark suite. Columbo then uses a rule-based methodology to recommend parameter updates based on the detected bottleneck, deployed workload, and mapping of configurations to pipeline stages. We demonstrate that Columbo reduces workload deployment time across its benchmark suite by 28% on average and 79% at most. We report a total execution time decrease of 17% for data processing with Spark and up to 20% for serverless workflows with OpenWhisk. Columbo is open-source and available at https://github.com/atlarge-research/continuum/tree/columbo.
@inproceedings{columbo2025jansen, author = {Jansen, Matthijs and Talluri, Sacheendra and Doekemeijer, Krijn and Tehrany, Nick and Iosup, Alexandru and Trivedi, Animesh}, title = {Columbo: A Reasoning Framework for Kubernetes' Configuration Space}, booktitle = {Proceedings of the 16th {ACM/SPEC} International Conference on Performance Engineering, {ICPE} 2025, Toronto, Canada, May 5-9, 2025}, publisher = {{ACM}}, year = {2025} } -
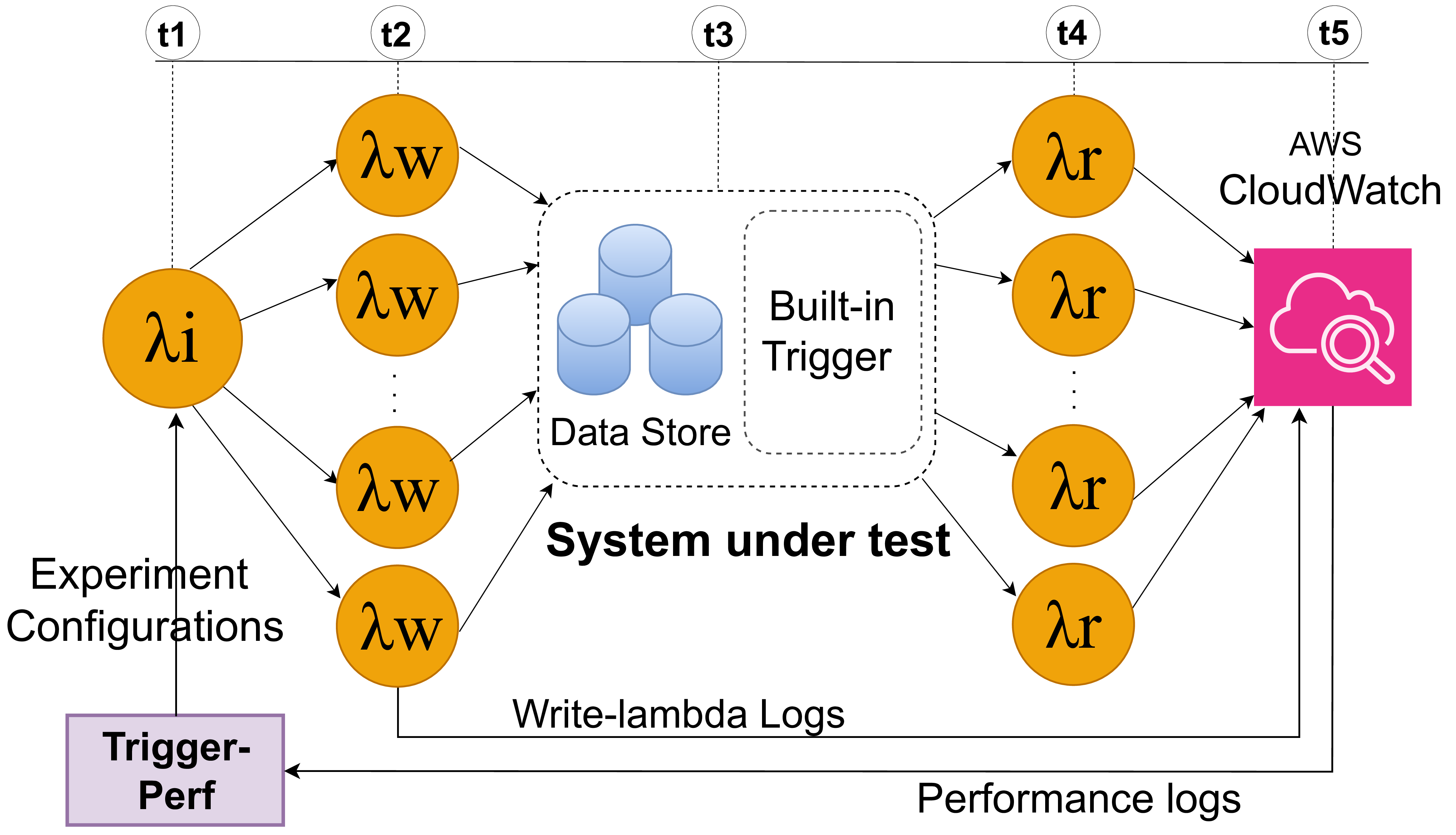 Performance Characterization of Data Store Event Trigger Mechanisms for Serverless ComputingRitul Satish, Sacheendra Talluri, Sudarsan Sivakumar, Matthijs Jansen, and Alexandru IosupIn Proceedings of the 25th IEEE International Symposium on Cluster, Cloud, and Internet Computing (CCGRID 2025), Tromsø, Norway, May 19-22, 2025, 2025
Performance Characterization of Data Store Event Trigger Mechanisms for Serverless ComputingRitul Satish, Sacheendra Talluri, Sudarsan Sivakumar, Matthijs Jansen, and Alexandru IosupIn Proceedings of the 25th IEEE International Symposium on Cluster, Cloud, and Internet Computing (CCGRID 2025), Tromsø, Norway, May 19-22, 2025, 2025Serverless applications are composed of functions triggered by events. Data stores are a common source of event triggers in the cloud, even beyond serverless, such as in Kubernetes. We find trigger latency, the time from event generation to function invocation, to take up to 62% of execution time for common serverless applications. Even though event triggers play a crucial role in serverless performance, the mechanisms driving these triggers are ill-understood. In this paper, we analyze data store trigger mechanisms, define the features that make up these mechanisms, and characterize their performance with TriggerPerf, a benchmarking tool for data store triggers. We implement TriggerPerf on three AWS data stores with built-in trigger support: S3, DynamoDB, and AuroraDB. With TriggerPerf, we demonstrate significant latency, scalability, and elasticity bottlenecks across these data stores. We observe that the trigger latency of AWS data stores is up to 100x higher compared to a reference etcd data store. Moreover, the median tail latency of S3 and AuroraDB is 10x higher when under high load, unlike DynamoDB. The observed variability in performance patterns significantly impacts the reliability of serverless and distributed systems that depend on them, highlighting the critical need for further research into the underlying mechanisms. The tool is open-sourced and is available for use at https://github.com/atlarge-research/trigger-perf.
@inproceedings{trigger2025satish, author = {Satish, Ritul and Talluri, Sacheendra and Sivakumar, Sudarsan and Jansen, Matthijs and Iosup, Alexandru}, booktitle = {Proceedings of the 25th {IEEE} International Symposium on Cluster, Cloud, and Internet Computing (CCGRID 2025), Tromsø, Norway, May 19-22, 2025}, title = {Performance Characterization of Data Store Event Trigger Mechanisms for Serverless Computing}, year = {2025}, publisher = {{IEEE}} } -
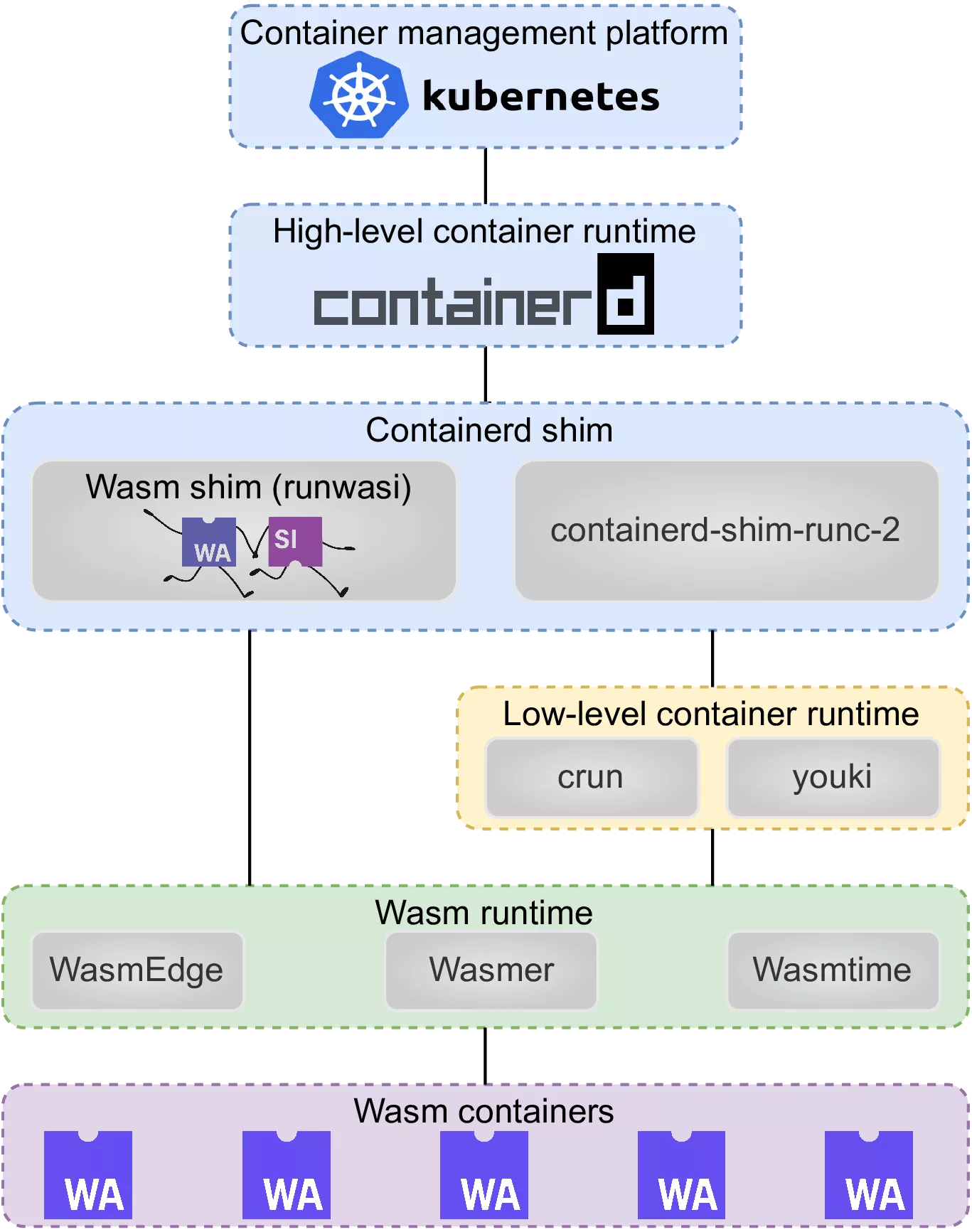 Memory Efficient WebAssembly ContainersMatthijs Jansen, Maciej Kozub, Alexandru Iosup, and Daniele BonettaIn IEEE International Parallel and Distributed Processing Symposium, IPDPS 2025 - Workshop, Milan, Italy, June 3-7, 2025, 2025
Memory Efficient WebAssembly ContainersMatthijs Jansen, Maciej Kozub, Alexandru Iosup, and Daniele BonettaIn IEEE International Parallel and Distributed Processing Symposium, IPDPS 2025 - Workshop, Milan, Italy, June 3-7, 2025, 2025WebAssembly (Wasm) is a portable, high-performance binary instruction format originally designed for web browsers. It is rapidly gaining traction in server-side applications, including containerized environments orchestrated by Kubernetes. However, the performance impact of a widespread WebAssembly adoption in containerized environments remains unclear. Solutions relying on suboptimal WebAssembly runtimes may increase performance and memory overhead, especially in high-density deployment settings. In this paper, we explore the impact of WebAssembly runtimes on containerized application deployment in Kubernetes. Through an in-depth analysis of existing Wasm container runtimes, we identify inefficiencies in memory usage and startup times, limiting Wasm’s viability in large-scale deployments. We propose a new integration of the lightweight WebAssembly Micro Runtime (WAMR) into the crun container runtime to resolve the identified inefficiencies of Wasm containers. Benchmark evaluations demonstrate that our WAMR integration reduces memory usage by 11% to 78% per container compared to existing Wasm runtimes while outperforming 4 of 6 benchmarked runtimes in container startup time. Furthermore, our integration reduces memory usage compared to Python containers by at least 16% and startup time by 3% to 18%. Our findings show that Wasm containers are a competitive alternative to traditional non-Wasm container solutions, especially in dense container deployments, and highlight the importance of runtime optimization in cloud-native environments. Our work is open-source and available at https://github.com/atlarge-research/continuum/tree/wasm.
@inproceedings{wasm2025jansen, author = {Jansen, Matthijs and Kozub, Maciej and Iosup, Alexandru and Bonetta, Daniele}, title = {Memory Efficient WebAssembly Containers}, booktitle = {{IEEE} International Parallel and Distributed Processing Symposium, {IPDPS} 2025 - Workshop, Milan, Italy, June 3-7, 2025}, publisher = {{IEEE}}, year = {2025} }
2024
-
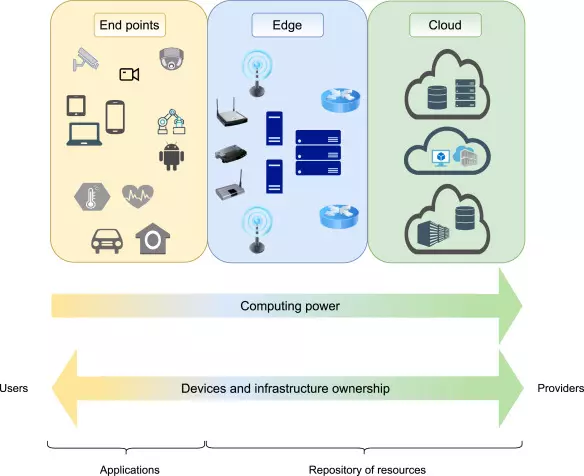 The computing continuum: From IoT to the cloudAuday Al-Dulaimy, Matthijs Jansen, Bjarne Johansson, Animesh Trivedi, Alexandru Iosup, Mohammad Ashjaei, Antonino Galletta, Dragi Kimovski, Radu Prodan, Konstantinos Tserpes, and 6 more authorsInternet of Things, 2024
The computing continuum: From IoT to the cloudAuday Al-Dulaimy, Matthijs Jansen, Bjarne Johansson, Animesh Trivedi, Alexandru Iosup, Mohammad Ashjaei, Antonino Galletta, Dragi Kimovski, Radu Prodan, Konstantinos Tserpes, and 6 more authorsInternet of Things, 2024In the era of the IoT revolution, applications are becoming ever more sophisticated and accompanied by diverse functional and non-functional requirements, including those related to computing resources and performance levels. Such requirements make the development and implementation of these applications complex and challenging. Computing models, such as cloud computing, can provide applications with on-demand computation and storage resources to meet their needs. Although cloud computing is a great enabler for IoT and endpoint devices, its limitations make it unsuitable to fulfill all design goals of novel applications and use cases. Instead of only relying on cloud computing, leveraging and integrating resources at different layers (like IoT, edge, and cloud) is necessary to form and utilize a computing continuum. The layers’ integration in the computing continuum offers a wide range of innovative services, but it introduces new challenges (e.g., monitoring performance and ensuring security) that need to be investigated. A better grasp and more profound understanding of the computing continuum can guide researchers and developers in tackling and overcoming such challenges. Thus, this paper provides a comprehensive and unified view of the computing continuum. The paper discusses computing models in general with a focus on cloud computing, the computing models that emerged beyond the cloud, and the communication technologies that enable computing in the continuum. In addition, two novel reference architectures are presented in this work: one for edge-cloud computing models and the other for edge–cloud communication technologies. We demonstrate real use cases from different application domains (like industry and science) to validate the proposed reference architectures, and we show how these use cases map onto the reference architectures. Finally, the paper highlights key points that express the authors’ vision about efficiently enabling and utilizing the computing continuum in the future.
@article{ALDULAIMY2024101272, author = {Al-Dulaimy, Auday and Jansen, Matthijs and Johansson, Bjarne and Trivedi, Animesh and Iosup, Alexandru and Ashjaei, Mohammad and Galletta, Antonino and Kimovski, Dragi and Prodan, Radu and Tserpes, Konstantinos and Kousiouris, George and Giannakos, Chris and Brandic, Ivona and Ali, Nawfal and Bondi, André B. and Papadopoulos, Alessandro V.}, journal = {Internet of Things}, title = {The computing continuum: From IoT to the cloud}, year = {2024}, volume = {27}, pages = {101272}, issn = {2542-6605}, doi = {https://doi.org/10.1016/j.iot.2024.101272}, url = {https://www.sciencedirect.com/science/article/pii/S2542660524002130}, keywords = {Computing continuum, Cloud computing, Fog computing, Edge computing, Mobile cloud computing, Multi-access edge computing, SDN, NFV, IoT, Use case, Reference architecture} } -
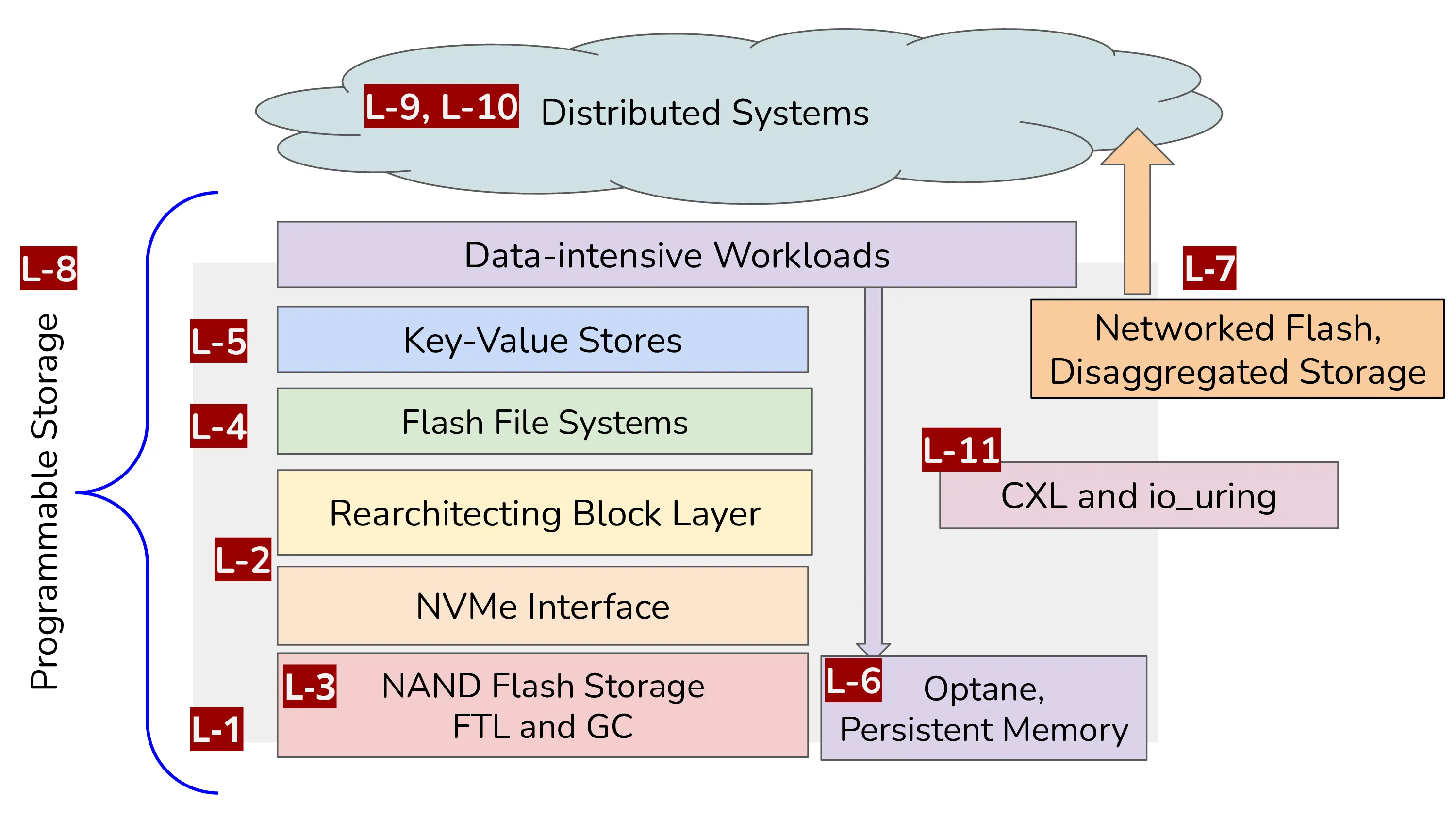 Reviving Storage Systems Education in the 21st Century — An experience reportAnimesh Trivedi, Matthijs Jansen, Krijn Doekemeijer, Sacheendra Talluri, and Nick TehranyIn 2024 IEEE 24th International Symposium on Cluster, Cloud and Internet Computing (CCGrid), 2024
Reviving Storage Systems Education in the 21st Century — An experience reportAnimesh Trivedi, Matthijs Jansen, Krijn Doekemeijer, Sacheendra Talluri, and Nick TehranyIn 2024 IEEE 24th International Symposium on Cluster, Cloud and Internet Computing (CCGrid), 2024We live in a data-centric world where many fundamental shifts in our daily lives are powered by Big Data. To meet the performance, cost, and energy demands of modern Big Data systems, there have been significant technological and engineering breakthroughs in the field of storage systems with novel hardware innovations and software architectures. Nevertheless, a typical computer science student still associates data storage solely with the technology of hard disk drives (HDD), which was invented six decades ago. One key reason for this association is the lack of courses on modern storage systems in computer science education curricula. In this paper, we make a concerted effort to summarize the state of storage systems education across universities, popular textbooks, and policies (ACM/IEEE). We make a case that the storage systems should have its own home course in educational curricula. We report on our experience of designing and offering one such course at the Vrije Universiteit, Amsterdam over the past four years. We further contribute to the educational material in this direction by making the course lectures, video recordings, assignments, and grading framework freely and openly accessible at https://atlarge-research.com/courses/storage-systems-vu.
@inproceedings{2024-ccgrid-stosys-edu, author = {Trivedi, Animesh and Jansen, Matthijs and Doekemeijer, Krijn and Talluri, Sacheendra and Tehrany, Nick}, booktitle = {2024 IEEE 24th International Symposium on Cluster, Cloud and Internet Computing (CCGrid)}, title = {Reviving Storage Systems Education in the 21st Century — An experience report}, year = {2024}, volume = {}, number = {}, pages = {616-625}, keywords = {Technological innovation;Costs;Software architecture;Education;Memory;Big Data;Hard disks;Hardware;Computer science education;Video recording;Storage systems;Education;Experience report}, doi = {10.1109/CCGrid59990.2024.00074} }
2023
-
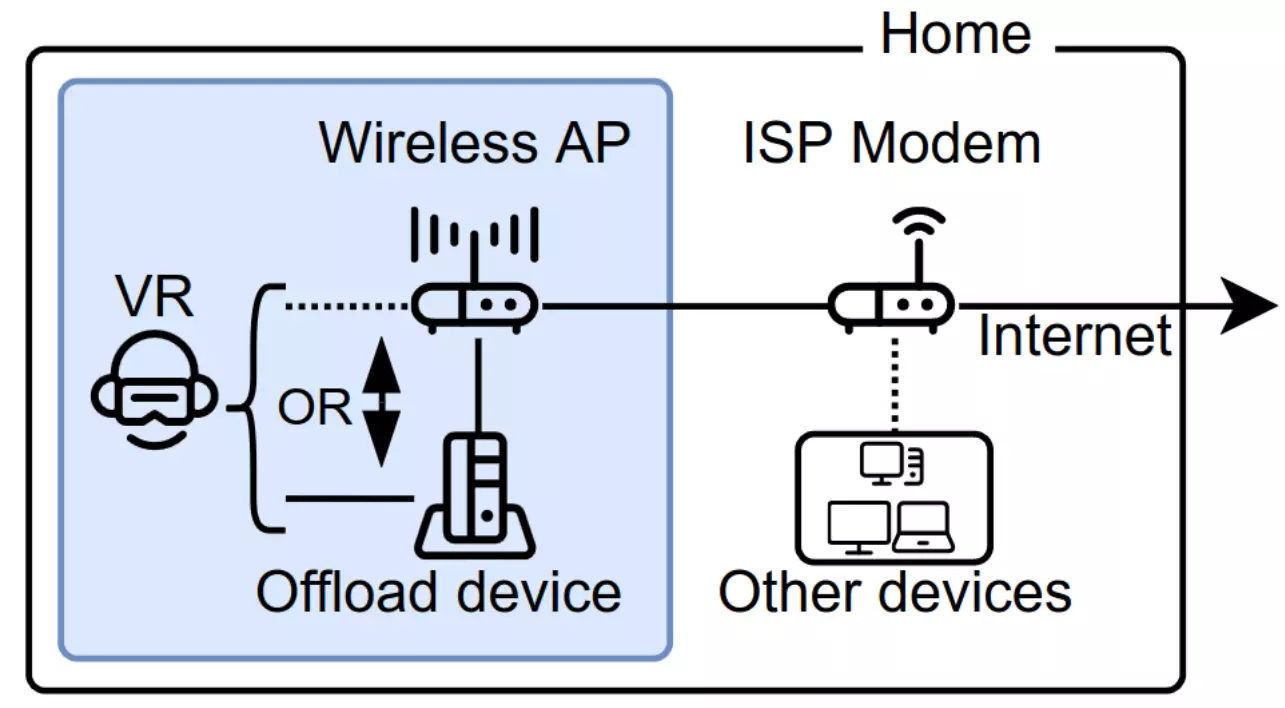 Can My WiFi Handle the Metaverse? A Performance Evaluation Of Meta’s Flagship Virtual Reality HardwareMatthijs Jansen, Jesse Donkervliet, Animesh Trivedi, and Alexandru IosupIn Companion of the 2023 ACM/SPEC International Conference on Performance Engineering, ICPE 2023, Coimbra, Portugal, April 15-19, 2023, 2023
Can My WiFi Handle the Metaverse? A Performance Evaluation Of Meta’s Flagship Virtual Reality HardwareMatthijs Jansen, Jesse Donkervliet, Animesh Trivedi, and Alexandru IosupIn Companion of the 2023 ACM/SPEC International Conference on Performance Engineering, ICPE 2023, Coimbra, Portugal, April 15-19, 2023, 2023Extending human societies into virtual space through the construction of a metaverse has been a long-term challenge in both industry and academia. Achieving this challenge is now closer than ever due to advances in computer systems, facilitating large-scale online platforms such as Minecraft and Roblox that fulfill an increasing number of societal needs, and extended reality (XR) hardware, which provides users with state-of-the-art immersive experiences. For a metaverse to succeed, we argue that all involved systems must provide consistently good performance. However, there is a lack of knowledge on the performance characteristics of extended reality devices. In this paper, we address this gap and focus on extended- and virtual-reality hardware. We synthesize a user-centered system model that models common deployments of XR hardware and their trade-offs. Based on this model, we design and conduct real-world experiments with Meta’s flagship virtual reality device, the Quest Pro. We highlight two surprising results from our findings which show that (i) under our workload, the battery drains 15% faster when using wireless offloading compared to local execution, and (ii) the outdated 2.4 GHz WiFi4 gives surprisingly good performance, with 99% of samples achieving a frame rate of at least 65 Hz, compared to the 72 Hz performance target. Our experimental setup and data are available at https://github.com/atlarge-research/measuring-the-metaverse.
@inproceedings{DBLP:conf/wosp/JansenDTI23, author = {Jansen, Matthijs and Donkervliet, Jesse and Trivedi, Animesh and Iosup, Alexandru}, editor = {Vieira, Marco and Cardellini, Valeria and Marco, Antinisca Di and Tuma, Petr}, title = {Can My WiFi Handle the Metaverse? {A} Performance Evaluation Of Meta's Flagship Virtual Reality Hardware}, booktitle = {Companion of the 2023 {ACM/SPEC} International Conference on Performance Engineering, {ICPE} 2023, Coimbra, Portugal, April 15-19, 2023}, pages = {297--303}, publisher = {{ACM}}, year = {2023}, url = {https://doi.org/10.1145/3578245.3585022}, doi = {10.1145/3578245.3585022}, timestamp = {Sat, 29 Apr 2023 19:25:35 +0200}, biburl = {https://dblp.org/rec/conf/wosp/JansenDTI23.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} } -
 Continuum: Automate Infrastructure Deployment and Benchmarking in the Compute ContinuumMatthijs Jansen, Linus Wagner, Animesh Trivedi, and Alexandru IosupIn Companion of the 2023 ACM/SPEC International Conference on Performance Engineering, ICPE 2023, Coimbra, Portugal, April 15-19, 2023, 2023
Continuum: Automate Infrastructure Deployment and Benchmarking in the Compute ContinuumMatthijs Jansen, Linus Wagner, Animesh Trivedi, and Alexandru IosupIn Companion of the 2023 ACM/SPEC International Conference on Performance Engineering, ICPE 2023, Coimbra, Portugal, April 15-19, 2023, 2023As the next generation of diverse workloads like autonomous driving and augmented/virtual reality evolves, computation is shifting from cloud-based services to the edge, leading to the emergence of a cloud-edge compute continuum. This continuum promises a wide spectrum of deployment opportunities for workloads that can leverage the strengths of cloud (scalable infrastructure, high reliability), edge (energy efficient, low latencies), and endpoints (sensing, user-owned). Designing and deploying software in the continuum is complex because of the variety of available hardware, each with unique properties and trade-offs. In practice, developers have limited access to these resources, limiting their ability to create software deployments. To simplify research and development in the compute continuum, in this paper, we propose Continuum, a framework for automated infrastructure deployment and benchmarking that helps researchers and engineers to deploy and test their use cases in a few lines of code. Continuum can automatically deploy a wide variety of emulated infrastructures and networks locally and in the cloud, install software for operating services and resource managers, and deploy and benchmark applications for users with diverse configuration options. In our evaluation, we show how our design covers these requirements, allowing Continuum to be (i) highly flexible, supporting any computing model, (ii) highly configurable, allowing users to alter framework components using an intuitive API, and (iii) highly extendable, allowing users to add support for more infrastructure, applications, and more. Continuum is available at https://github.com/atlarge-research/continuum.
@inproceedings{DBLP:conf/wosp/JansenWTI23, author = {Jansen, Matthijs and Wagner, Linus and Trivedi, Animesh and Iosup, Alexandru}, editor = {Vieira, Marco and Cardellini, Valeria and Marco, Antinisca Di and Tuma, Petr}, title = {Continuum: Automate Infrastructure Deployment and Benchmarking in the Compute Continuum}, booktitle = {Companion of the 2023 {ACM/SPEC} International Conference on Performance Engineering, {ICPE} 2023, Coimbra, Portugal, April 15-19, 2023}, pages = {181--188}, publisher = {{ACM}}, year = {2023}, url = {https://doi.org/10.1145/3578245.3584936}, doi = {10.1145/3578245.3584936}, timestamp = {Sat, 29 Apr 2023 19:25:34 +0200}, biburl = {https://dblp.org/rec/conf/wosp/JansenWTI23.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} } -
 The SPEC-RG Reference Architecture for The Compute ContinuumMatthijs Jansen, Auday Al-Dulaimy, Alessandro V. Papadopoulos, Animesh Trivedi, and Alexandru IosupIn 23rd IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing, CCGrid 2023, Bangalore, India, May 1-4, 2023, 2023
The SPEC-RG Reference Architecture for The Compute ContinuumMatthijs Jansen, Auday Al-Dulaimy, Alessandro V. Papadopoulos, Animesh Trivedi, and Alexandru IosupIn 23rd IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing, CCGrid 2023, Bangalore, India, May 1-4, 2023, 2023As the next generation of diverse workloads like autonomous driving and augmented/virtual reality evolves, computation is shifting from cloud-based services to the edge, leading to the emergence of a cloud-edge compute continuum. This continuum promises a wide spectrum of deployment opportunities for workloads that can leverage the strengths of cloud (scalable infrastructure, high reliability) and edge (energy efficient, low latencies). Despite its promises, the continuum has only been studied in silos of various computing models, thus lacking strong end-to-end theoretical and engineering foundations for computing and resource management across the continuum. Consequently, devel-opers resort to ad hoc approaches to reason about performance and resource utilization of workloads in the continuum. In this work, we conduct a first-of-its-kind systematic study of various computing models, identify salient properties, and make a case to unify them under a compute continuum reference architecture. This architecture provides an end-to-end analysis framework for developers to reason about resource management, workload distribution, and performance analysis. We demonstrate the utility of the reference architecture by analyzing two popular continuum workloads, deep learning and industrial IoT. We have developed an accompanying deployment and benchmarking framework and first-order analytical model for quantitative reasoning of continuum workloads. The framework is open-sourced and available at https://github.com/atlarge-research/continuum.
@inproceedings{DBLP:conf/ccgrid/JansenAPTI23, author = {Jansen, Matthijs and Al{-}Dulaimy, Auday and Papadopoulos, Alessandro V. and Trivedi, Animesh and Iosup, Alexandru}, editor = {Simmhan, Yogesh and Altintas, Ilkay and Varbanescu, Ana Lucia and Balaji, Pavan and Prasad, Abhinandan S. and Carnevale, Lorenzo}, title = {The {SPEC-RG} Reference Architecture for The Compute Continuum}, booktitle = {23rd {IEEE/ACM} International Symposium on Cluster, Cloud and Internet Computing, CCGrid 2023, Bangalore, India, May 1-4, 2023}, pages = {469--484}, publisher = {{IEEE}}, year = {2023}, url = {https://doi.org/10.1109/CCGrid57682.2023.00051}, doi = {10.1109/CCGrid57682.2023.00051}, timestamp = {Fri, 21 Jul 2023 22:25:52 +0200}, biburl = {https://dblp.org/rec/conf/ccgrid/JansenAPTI23.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} } -
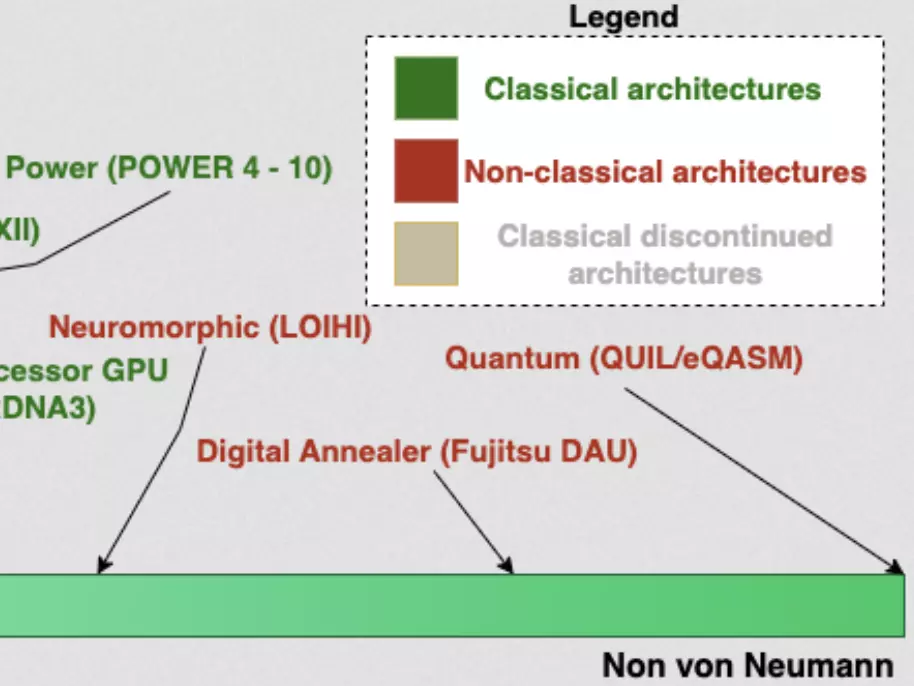 Beyond von Neumann in the Computing Continuum: Architectures, Applications, and Future DirectionsDragi Kimovski, Nishant Saurabh, Matthijs Jansen, Atakan Aral, Auday Al-Dulaimy, André B. Bondi, Antonino Galletta, Alessandro V. Papadopoulos, Alexandru Iosup, and Radu ProdanIEEE Internet Computing, 2023
Beyond von Neumann in the Computing Continuum: Architectures, Applications, and Future DirectionsDragi Kimovski, Nishant Saurabh, Matthijs Jansen, Atakan Aral, Auday Al-Dulaimy, André B. Bondi, Antonino Galletta, Alessandro V. Papadopoulos, Alexandru Iosup, and Radu ProdanIEEE Internet Computing, 2023The article discusses the emerging non-von Neumann computer architectures and their integration in the computing continuum for supporting modern distributed applications, including artificial intelligence, big data, and scientific computing. It provides a detailed summary of the available and emerging non-von Neumann architectures, which range from power-efficient single-board accelerators to quantum and neuromorphic computers. Furthermore, it explores their potential benefits for revolutionizing data processing and analysis in various societal, science, and industry fields. The paper provides a detailed analysis of the most widely used class of distributed applications and discusses the difficulties in their execution over the computing continuum, including communication, interoperability, orchestration, and sustainability issues.
@article{10207712, author = {Kimovski, Dragi and Saurabh, Nishant and Jansen, Matthijs and Aral, Atakan and Al-Dulaimy, Auday and Bondi, André B. and Galletta, Antonino and Papadopoulos, Alessandro V. and Iosup, Alexandru and Prodan, Radu}, journal = {IEEE Internet Computing}, title = {Beyond von Neumann in the Computing Continuum: Architectures, Applications, and Future Directions}, year = {2023}, volume = {}, number = {}, pages = {1-11}, doi = {10.1109/MIC.2023.3301010} }
2021
-
 GradeML: Towards Holistic Performance Analysis for Machine Learning WorkflowsTim Hegeman, Matthijs Jansen, Alexandru Iosup, and Animesh TrivediIn ICPE ’21: ACM/SPEC International Conference on Performance Engineering, Virtual Event, France, April 19-21, 2021, Companion Volume, 2021
GradeML: Towards Holistic Performance Analysis for Machine Learning WorkflowsTim Hegeman, Matthijs Jansen, Alexandru Iosup, and Animesh TrivediIn ICPE ’21: ACM/SPEC International Conference on Performance Engineering, Virtual Event, France, April 19-21, 2021, Companion Volume, 2021Today, machine learning (ML) workloads are nearly ubiquitous. Over the past decade, much effort has been put into making ML model-training fast and efficient, e.g., by proposing new ML frameworks (such as TensorFlow, PyTorch), leveraging hardware support (TPUs, GPUs, FPGAs), and implementing new execution models (pipelines, distributed training). Matching this trend, considerable effort has also been put into performance analysis tools focusing on ML model-training. However, as we identify in this work, ML model training rarely happens in isolation and is instead one step in a larger ML workflow. Therefore, it is surprising that there exists no performance analysis tool that covers the entire life-cycle of ML workflows. Addressing this large conceptual gap, we envision in this work a holistic performance analysis tool for ML workflows. We analyze the state-of-practice and the state-of-the-art, presenting quantitative evidence about the performance of existing performance tools. We formulate our vision for holistic performance analysis of ML workflows along four design pillars: a unified execution model, lightweight collection of performance data, efficient data aggregation and presentation, and close integration in ML systems. Finally, we propose first steps towards implementing our vision as GradeML, a holistic performance analysis tool for ML workflows. Our preliminary work and experiments are open source at https://github.com/atlarge-research/grademl.
@inproceedings{DBLP:conf/wosp/HegemanJIT21, author = {Hegeman, Tim and Jansen, Matthijs and Iosup, Alexandru and Trivedi, Animesh}, editor = {Bourcier, Johann and Jiang, Zhen Ming (Jack) and Bezemer, Cor{-}Paul and Cortellessa, Vittorio and Pompeo, Daniele Di and Varbanescu, Ana Lucia}, title = {GradeML: Towards Holistic Performance Analysis for Machine Learning Workflows}, booktitle = {{ICPE} '21: {ACM/SPEC} International Conference on Performance Engineering, Virtual Event, France, April 19-21, 2021, Companion Volume}, pages = {57--63}, publisher = {{ACM}}, year = {2021}, url = {https://doi.org/10.1145/3447545.3451185}, doi = {10.1145/3447545.3451185}, timestamp = {Sun, 02 Oct 2022 16:17:46 +0200}, biburl = {https://dblp.org/rec/conf/wosp/HegemanJIT21.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
2020
-
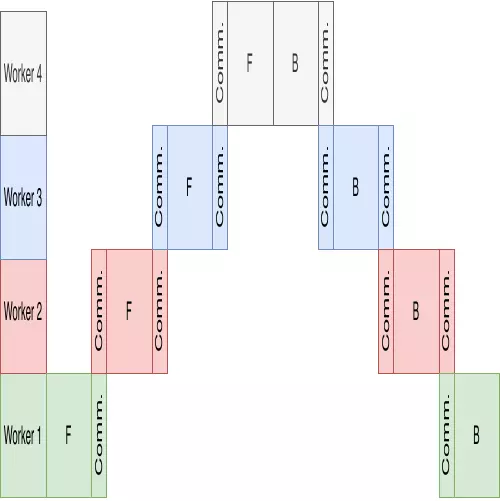 DDLBench: Towards a Scalable Benchmarking Infrastructure for Distributed Deep LearningMatthijs Jansen, Valeriu Codreanu, and Ana Lucia VarbanescuIn Deep Learning on Supercomputers, 2020
DDLBench: Towards a Scalable Benchmarking Infrastructure for Distributed Deep LearningMatthijs Jansen, Valeriu Codreanu, and Ana Lucia VarbanescuIn Deep Learning on Supercomputers, 2020Due to its many applications across various fields of research, engineering, and daily life, deep learning has seen a surge in popularity. Therefore, larger and more expressive models have been proposed, with examples like Turing-NLG using as many as 17 billion parameters. Training these very large models becomes increasingly difficult due to the high computational costs and large memory footprint. Therefore, several approaches for distributed training based on data parallelism (e.g., Horovod) and model/pipeline parallelism (e.g., GPipe, PipeDream) have emerged. In this work, we focus on an in-depth comparison of three different parallelism models that address these needs: data, model and pipeline parallelism. To this end, we provide an analytical comparison of the three, both in terms of computation time and memory usage, and introduce DDLBench, a comprehensive (open-source, ready-to-use) benchmark suite to quantify these differences in practice. Through in-depth performance analysis and experimentation with various models, datasets, distribution models and hardware systems, we demonstrate that DDLBench can accurately quantify the capability of a given system to perform distributed deep learning (DDL). By comparing our analytical models with the benchmarking results, we show how the performance of real-life implementations diverges from these analytical models, thus requiring benchmarking to capture the in-depth complexity of the frameworks themselves.
@inproceedings{DBLP:conf/sc/JansenCV20, author = {Jansen, Matthijs and Codreanu, Valeriu and Varbanescu, Ana Lucia}, title = {DDLBench: Towards a Scalable Benchmarking Infrastructure for Distributed Deep Learning}, booktitle = {Deep Learning on Supercomputers}, pages = {31--39}, publisher = {{IEEE}}, year = {2020}, url = {https://doi.org/10.1109/DLS51937.2020.00009}, doi = {10.1109/DLS51937.2020.00009}, biburl = {https://dblp.org/rec/conf/sc/JansenCV20.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }